
Deep Learning Training Algorithms I: Introduction
1. Introduction
Deep learning has revolutionized the field of artificial intelligence, enabling machines to perform tasks that were previously thought to be exclusive to human intelligence. At the heart of deep learning lies the concept of training, which involves feeding a model with data, and adjusting its parameters to minimize the difference between the predicted and true values. Training is a crucial step in the development of any deep learning model, as it determines the accuracy of the model's predictions and its ability to generalize to new, unseen data.
However, training deep learning models is a computationally intensive process that requires the use of powerful algorithms. These algorithms, collectively known as training algorithms or optimization algorithms, are responsible for minimizing the error between the model's predicted outputs and the true outputs. The choice of training algorithm can have a significant impact on the model's performance, as different algorithms may converge to different local minima, have different convergence speeds, and require different amounts of computational resources.
In this blog post series, we will explore the most commonly used training algorithms in deep learning. We will cover gradient-based optimization algorithms, second-order optimization algorithms, conjugate gradient algorithms, and other optimization techniques such as weight decay, dropout, and batch normalization. By the end of this series, you will have a better understanding of the different training algorithms available and be equipped with the knowledge to choose the best algorithm for your specific deep learning model.
2. Main Categories of Training Algorithms
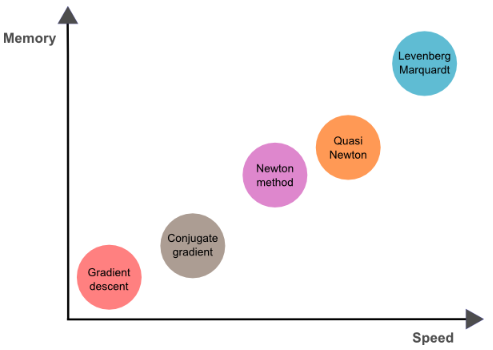
Training algorithms, also known as optimization algorithms, can be broadly classified into several categories based on their approach to minimizing the error between the predicted and true outputs of a deep learning model. These categories include:
2.1. Gradient-Based Optimization Algorithms
Gradient-based optimization algorithms, such as gradient descent and stochastic gradient descent, are the most widely used training algorithms in deep learning. These algorithms work by computing the gradient of the error function with respect to the model parameters and updating the parameters in the direction of the negative gradient. Gradient-based algorithms can be further classified into several subcategories, including
- Gradient Descent
- Stochastic Gradient Descent (SGD)
- Mini-Batch SGD
- Momentum
- Nesterov Accelerated Gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
- Adamax
- Nadam
2.2. Second-Order Optimization Algorithms
Second-order optimization algorithms, such as Newton's method and quasi-Newton methods, take into account the curvature of the error function in addition to its gradient. These algorithms are more computationally expensive than gradient-based algorithms but can converge faster and with fewer iterations. Some commonly used second-order optimization algorithms including:
- Newton's Method
- Quasi-Newton Methods
- Broyden-Fletcher-Goldfarb-Shanno (BFGS)
- Limited-memory BFGS (L-BFGS)
2.3. Conjugate Gradient Algorithms
Conjugate gradient algorithms are refered to as a particular type of second-order optimization algorithm that are specifically designed to work with large, sparse linear systems. These algorithms are particularly well-suited for training deep learning models with large numbers of parameters. Conjugate gradient algorithm can be divided further as:
- Conjugate Gradient
- Nonlinear Conjugate Gradient
2.4. Other Optimization Techniques
In addition to the above categories of training algorithms, there are many other optimization techniques that are commonly used in deep learning. These techniques include weight decay, dropout, and batch normalization, among others. These techniques are designed to help prevent overfitting and improve the generalization performance of deep learning models.
3. Summary
Deep learning training algorithms are a crucial component of building and training effective deep learning models. There are several categories of training algorithms that have been developed over the years, each with its own strengths and weaknesses. In this section, we have briefly introduced the main categories of training algorithms, including Gradient-Based Optimization Algorithms, Second-Order Optimization Algorithms, Conjugate Gradient Algorithms, and others. In future blog posts, we will dive deeper into each of these categories, exploring their underlying principles, advantages, and limitations. Stay tuned for more in-depth discussions on deep learning training algorithms!