How to deal with categorical features? And what is one-hot-encoding?

-
Categorical features usually indicate the type of observation. For instance, "Gender" can have two categories such as 'male' and 'female'.
-
There are several methods to handle categorical features, such as one-hot-encoding, target encoding, dummy encoding, hash encoding, etc.
-
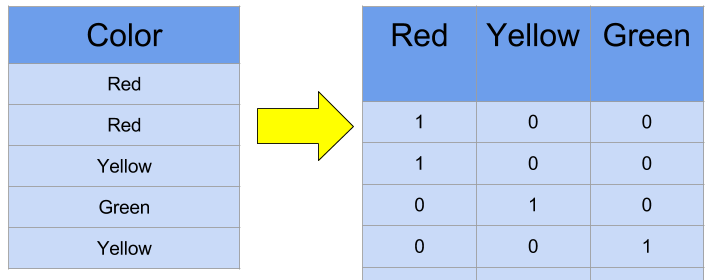
One-hot-encoding maps a k-category feature to a set of k binary variables. When the feature falls in the ith category, a “1” value is placed in the ith variable and “0” values for the other variables.
-
In regard to the previous gender example, one-hot-encoding maps 'Gender' to two binary variables. Their values can be taken as follows:
| Gender | Male | Female |
|---|---|---|
| variable-1 | 0 | 1 |
| variable-2 | 1 | 0 |
- Python code for one-hot-encoding:
from sklearn.preprocessing import OneHotEncoder
gender_encoder = OneHotEncoder()
gender_one_hot = gender_encoder.fit_transform(gender)
-
An issue of one-hot-encoding is that this representation makes redundancy, which causes multicollinearity in linear regression. With dummy encoding, for a k-category feature, we need only k-1 binary variables.
-
Back to the gender example, we need only one dummy variable \(D_g\), which takes values as follows:
| Gender | Male | Female |
|---|---|---|
| \( D_g \) | 0 | 1 |
- Python code for dummy-encoding:
import pandas as pd
pd.get_dummies(gender, dummy_na=True, , drop_first=True)