
Review of Deep Learning Algorithms and Architectures IV: Boltzmann Machine
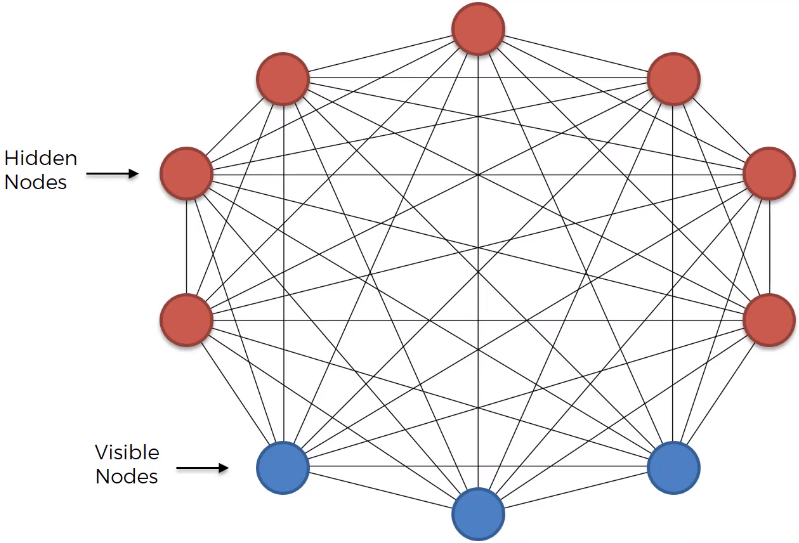
Boltzmann machines were originally introduced as a general "connectionist" approach to learning arbitrary probability distributions over binary vectors.
We define the Boltzmann machine over a $d-$dimensional binary random vector $\mathbf{x} \in \{0, 1 \}^{d}$. The Boltzmann machine is an energy-base model meaning we define the join probability distribution using an energy function:
$$P(\mathbf{x}) = \frac{exp(-E(\mathbf{x}))}{Z}$$
where $E(\mathbf{x})$ is the energy function and $Z$ is the partition function that ensures that $\sum_{\mathbf{x}} P(\mathbf{x})=1$.The energy function of the Boltzmann machine is given by
$$E(\mathbf{x})= -\mathbf{x}^{T}\mathbf{U}\mathbf{x} - \mathbf{b}^{T}\mathbf{x}$$
where $\mathbf{U}$ is the "weight" matrix of model parameters and $\mathbf{b}$ is the vector of bias parameters.
The Boltzmann machine becomes more powerful when not all the variables are observed. In this case, the non-observed variables, or latent variables, can act similarly to hidden units in a multi-layer perceptron and model higher-order interactions among the visible units.
Just as the addition of hidden units to convert logistic regression into an MLP (multi-layer perceptron) results in the MLP being a universal approximator of functions, a Boltzmann machine with hidden units is no longer limited to modeling linear relationships between variables. Instead, the Boltzmann machine becomes a universal approximator of probability mass functions over discrete variables.
Formally, we decompose the units $\mathbf{x}$ into two subsets: the visible units $\mathbf{v}$ and the latent (or hidden) units $\mathbf{h}$. The energy function becomes
$$E(\mathbf{x})= -\mathbf{v}^{T}\mathbf{R}\mathbf{v} -\mathbf{v}^{T}\mathbf{W}\mathbf{h} -\mathbf{h}^{T}\mathbf{S}\mathbf{h} - \mathbf{b}^{T}\mathbf{v} - \mathbf{c}^{T}\mathbf{h}.$$
Learning algorithms for Boltzmann machines are usually based on maximum likelihood. All Boltzmann machines have an intractable partition function, so the maximum likelihood gradient must be approximated using the techniques such as Gibbs sampling, contrastive divergence learning procedure, batching, etc.
Boltzmann machines experience a serious practical problem, namely that it seems to stop learning correctly when the machine is scaled up to anything larger than a trivial size. This is due to the important effects, specifically:
- The required time order to collect equilibrium statistics grows exponentially with the machine's size, and with the magnitude of the connection strengths.
- Connection strengths are more plastic when the connected units have activation probabilities intermediate between zero and one, leading to a so-called variance trap. The net effect is that noise causes the connection strengths to follow a random work until the activities saturate.
Although learning is impractical in general Boltzmann machines, it can be made quite efficient in a Restricted Boltzmann Machine (RBM) which does not allow intralayer connections between hidden units and visible units, i.e., there is no connection between visible to visible and hidden to hidden units.
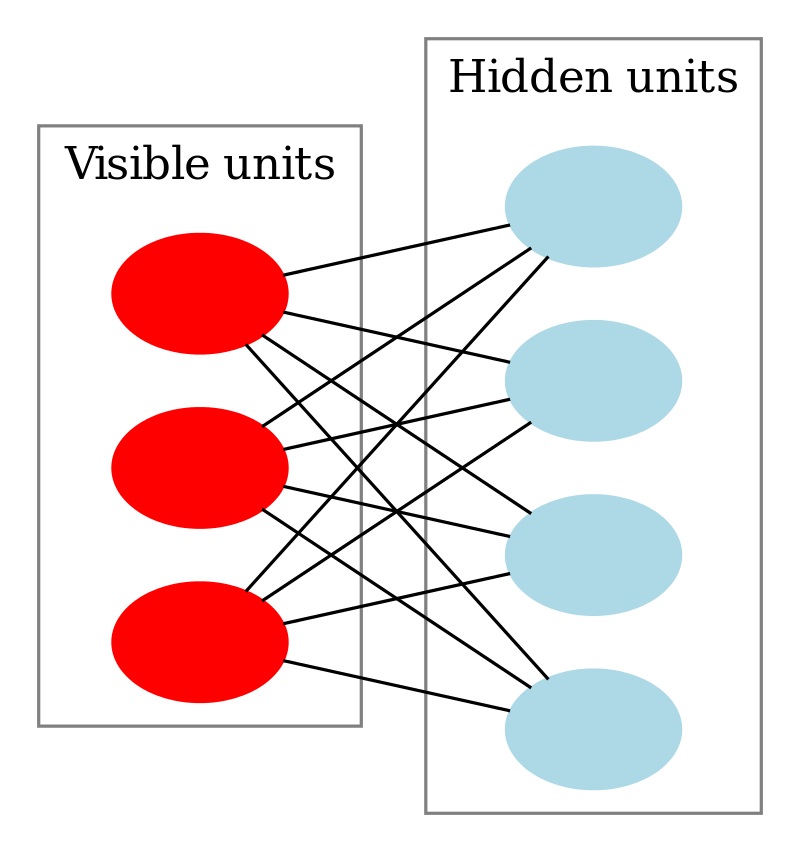
After training one RBM, the activities of its hidden units can be treated as data for training a higher-level RBM. This method of stacking RBMs makes it possible to train many layers of hidden units efficiently and is one of the most common deep-learning strategies.
A Deep Boltzmann Machine (DBM) is a kind of deep, generative model. Unlike the RBM, the DBM has several layers of latent variables (RBMs have just one). But like RBM, within each layer, each of the variables are mutually independent, conditioned on the variables in the neighboring layers.
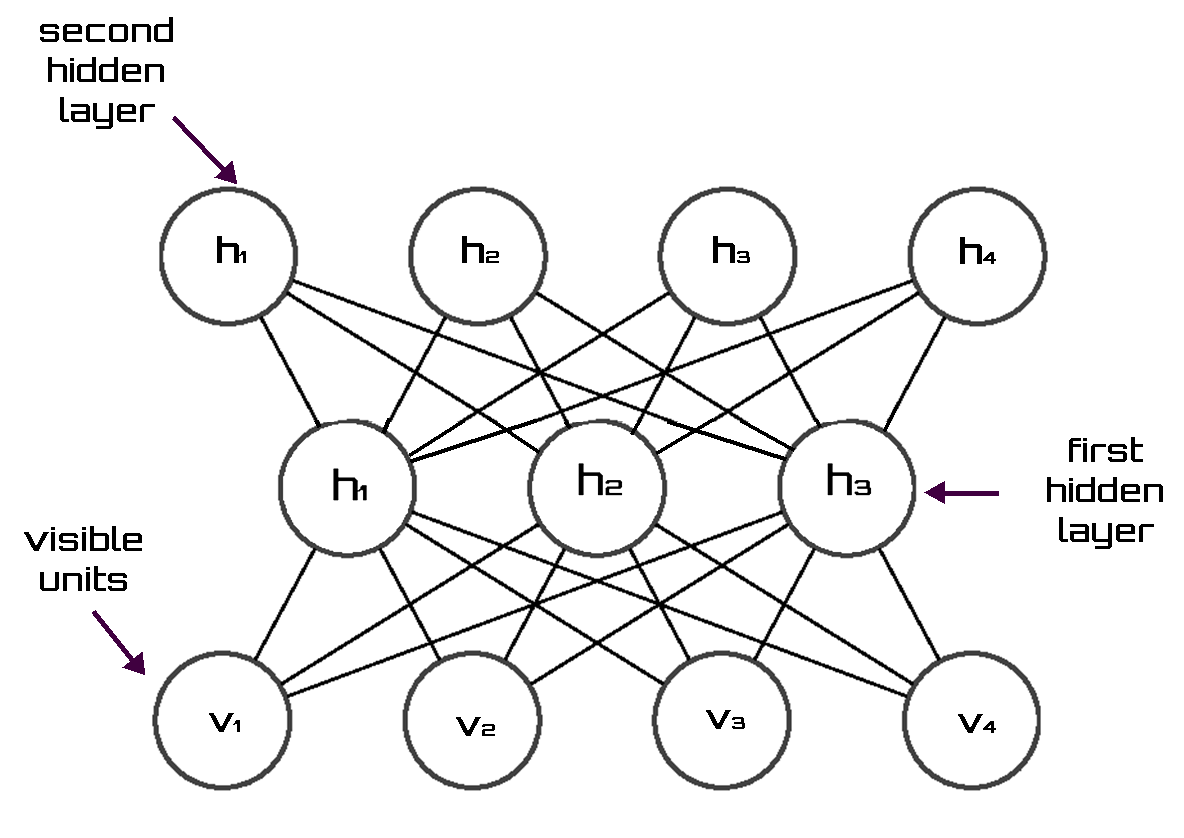
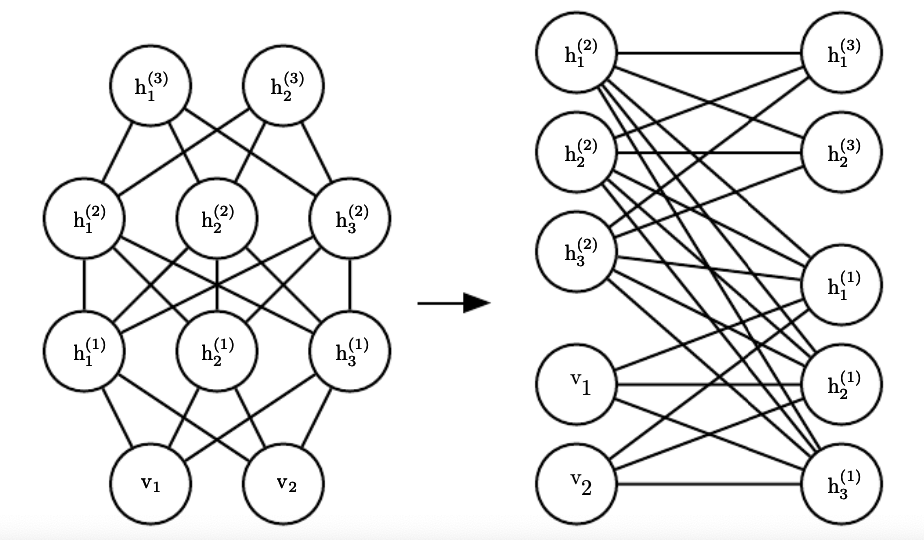
In comparison to fully connected Boltzmann machines, the DBM offers some advantages that are similar to those offered by the RBM. Specifically, as illustrated in the figure below, the DBM layers can be organized into a bipartite graph, with odd layers on one side and even layers on the other, the variables in the odd layers become conditionally independent. Of course, when we condition on the variables in the odd layers, the variables in the even layers also become conditionally independent.
Boltzmann Machines can be used in classification or probability-based problems. For instance, Srivastava et al. constructed a type of DBM that is suitable for extracting distributed semantic representations from a large unstructured collection of documents. They trained the model efficiently and showed that the model assigns better log probability to unseen data than the Replicated Softmax model. In addition, features extracted from the model outperform LDA, Replicated Softmax, and DocNADE models on document retrieval and document classification tasks.
Reference:
- Widipedia, Boltamann machine.
- Deep Learning, Ian Goodfellow, Yoshua Bengio, and Aaron Courville.
- Modeling Documents with a Deep Boltzmann Machine, Nitish Srivastava, Ruslan Salakhutdinov, and Geoffrey Hinton.
Except of the reference mentioned above, I highly recommended a video on Youtube, Restricted Boltzmann Machine (RBM) -- A friendly introduction, which is the most clear and illustrative explanation of RBM I've ever seen.