What is Streaming K-Means

-
Streaming k-means is a version of k-means where the dataset is fed in a stream rather than all dumped at one time.
-
To present this concept clearly. We will give a short explanation of k-means first, then we will interpret why streaming data do matter and what shall we change the algorithm to make it still work for the dynamic system.
1. K-Means Clustering
-
Given a set of points \((x_{1}, \ldots, x_{n})\) in \(d\)-dimensional Euclidean space \(\mathbb{R}^{d}\), K-Means clustering aims to partition the \(n\) points into \(k\) sets \(S = {S_{1}, \ldots, S_{k}}\) so as to minimize the within-cluster sum of squares (WCSS).
-
Let \(|x-y|\) denote the Euclidean distance between \(x\) and \(y\). Then the objective is to find:
\[\underset{\mathbf{S}}{\arg \min } \sum_{i=1}^{k} \sum_{\mathbf{x} \in S_{i}}\|\mathbf{x}-\boldsymbol{\mu}_{i}\|^{2}=\underset{\mathbf{S}}{\arg \min } \sum_{i=1}^{k}\left|S_{i}\right| \operatorname{Var} S_{i}\]
where \(\mu_{i}\) is the mean of points in \(S_{i}\).
- Algorithm for k-means clustering:
- Randomly choose k points from the dataset and uses these as the initial means.
- Assign each point to the cluster with the nearest mean.
- Recalculate means (centroids) for observations assigned to each cluster.
- Repeat Step 2 and Step 3, until the results converge.
2. Streaming K-Means Clustering
-
In the streaming setting, our data arrive in batches. If the whole dataset is homogeneous, then whether all the data is given at one time will not bother us at all. We can just perform naive k-means clustering and classify the new feeding-in points by our fitted model.
-
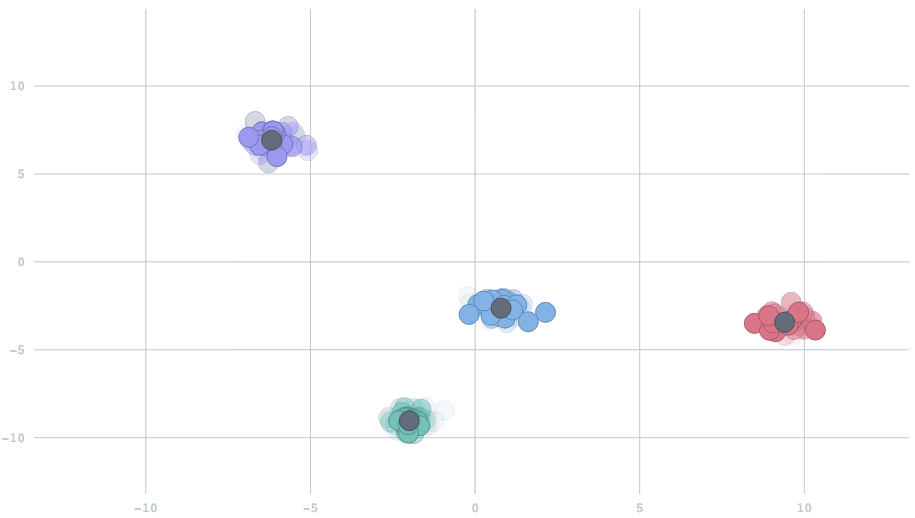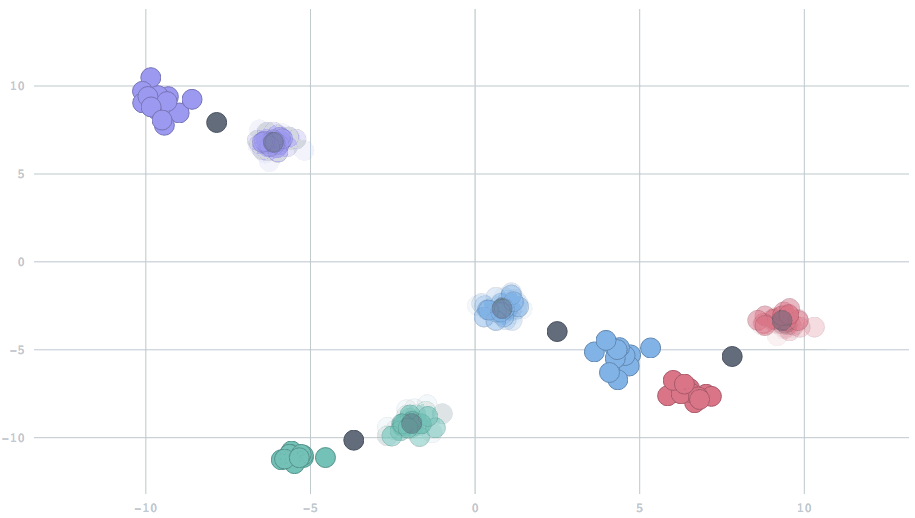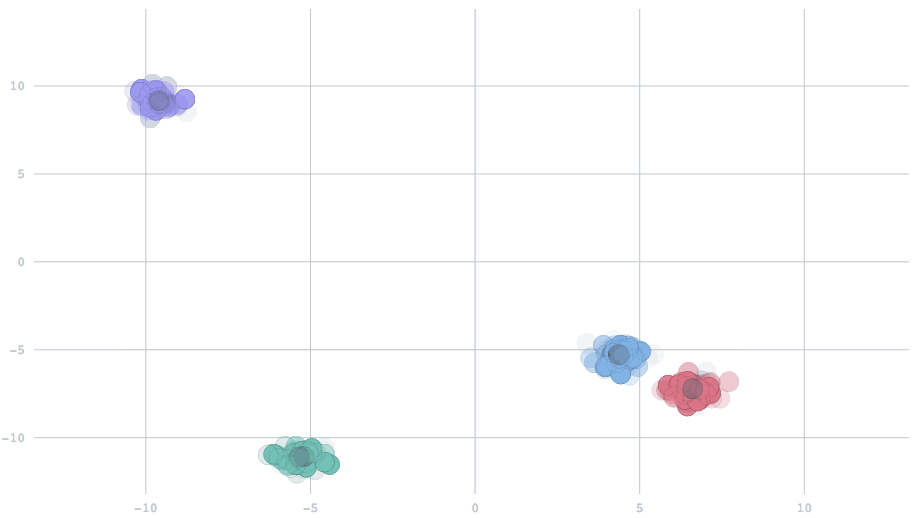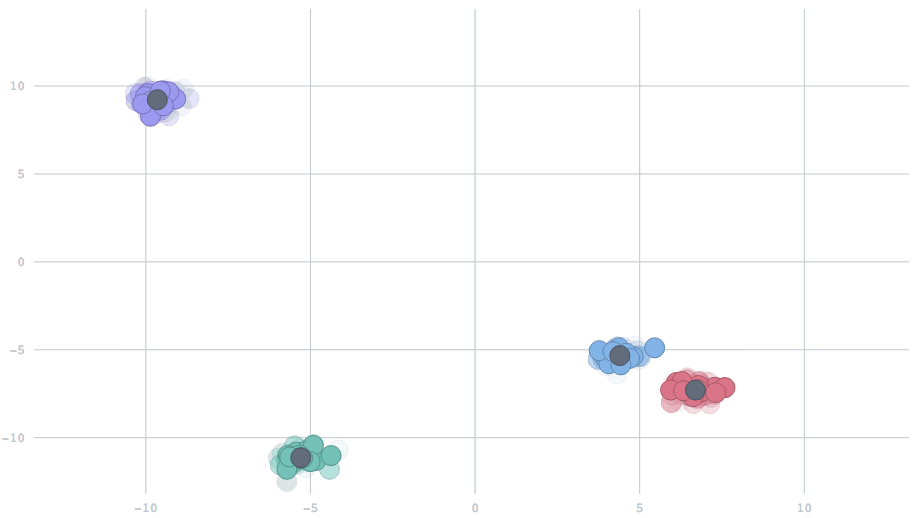
However, if the system is dynamic and the locations of centroids change over time, then we can't count on naive k-means anymore.
-
For this setting, a useful concept, named forgetfulness, is introduced to naive k-means. An extra parameter, decayFactor, which describes forgetfulness, should be preset in advance to adjust the speed of adaption.
-
When we set decayFactor to 0, all data from the beginning of time are treated equally. When we set it to 1, only the most recent data will be used. Settings in-between will combine the present with a partial reflection of the past.
-
Python code for streaming k-means:
from pyspark.mllib.clustering import StreamingKMeans
model = StreamingKMeans(k=4, decayFactor=1.0, timeUnit='batches')