What is AdaBoost classification?

-
Adaboost stands for Adaptive Boosting where a set of simple and weak classifiers is used to achieve an improved classifier by emphasizing the samples that are misclassified by weak classifiers.
-
For this concept, Sebastian Raschka & Vahid Mirjalili give a very clear explanation for it in their book Python Machine Learning.
-
First let's recall how original boosting algorithm procedures:
- Draw a random subset of training examples, \(d_1\), to train a weak learner, \(C_1\).
- Draw a second random training subset, \(d_2\), without replacement from the training dataset add 50 percent of the examples that were previously misclassified to train a weak learner, \(C_2\).
- Find the training examples, \(d_3\), in the training dataset, \(D\), which \(C_1\) and \(C_2\) disagree upon, to train a weak learner, \(C_3\).
- Combine the weak learners \(C_1\), \(C_2\), and \(C_3\) via majority voting.
-
In contrast to the original boosting procedure, AdaBoost uses the complete training dataset to train the weak learners, where the training examples are reweighted in each iteration to build a strong classifier that learns from the mistakes of the previous weak learners in the ensemble.
-
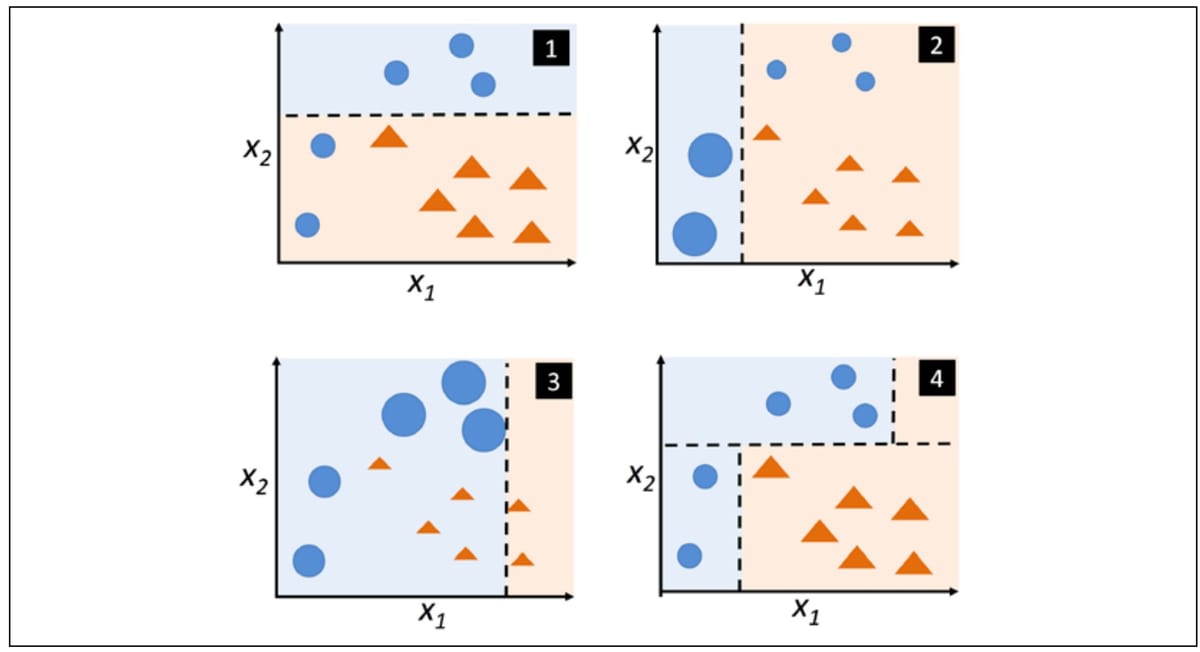
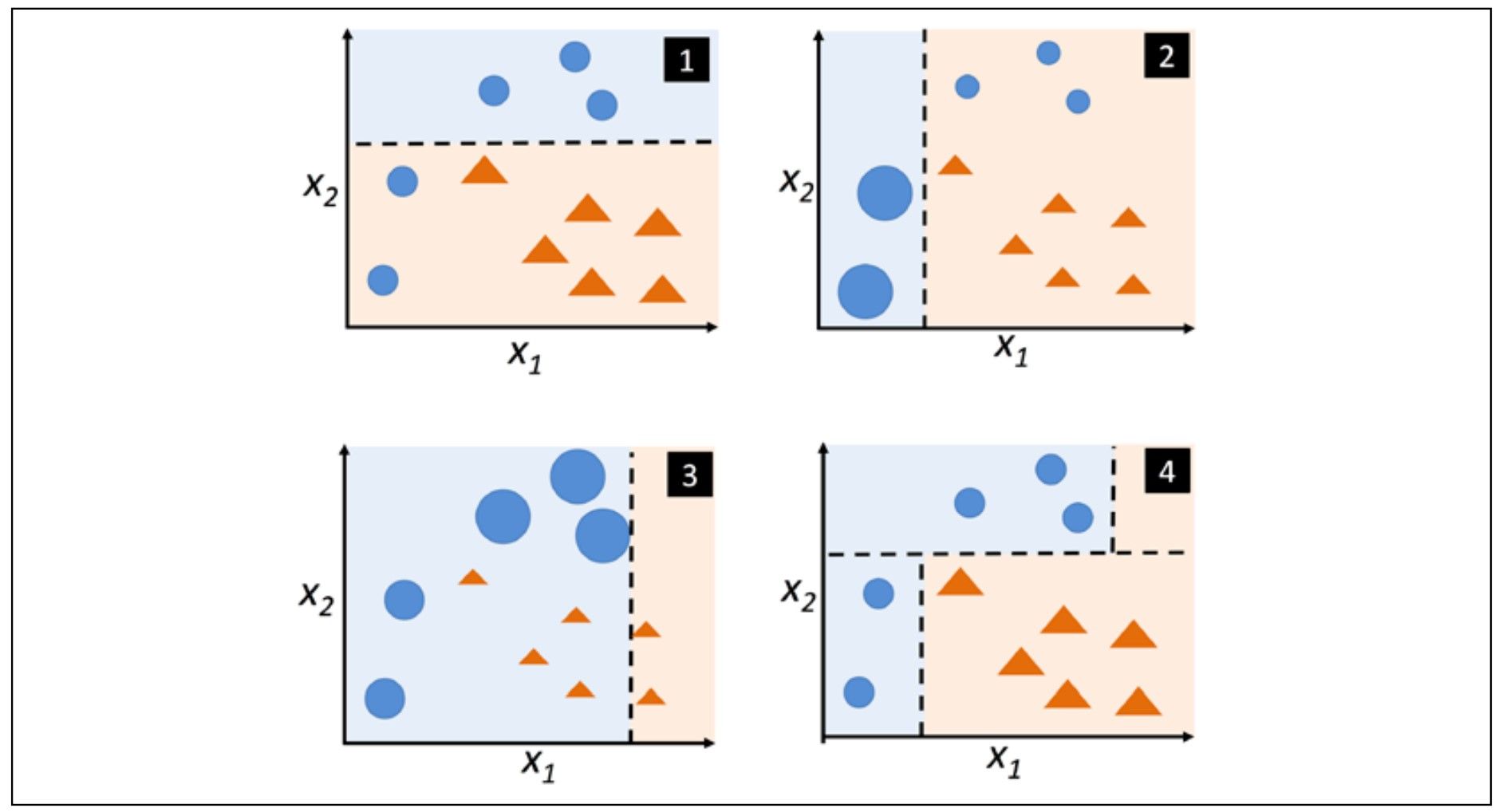
Before giving a further explanation for how AdaBoost algorithm procedure, we first show a figure to illustrate how AdaBoost works.
-
Now we will show you the pseudo-code for deploying AdaBoost algorithm.
- Set the weight vector, \(\boldsymbol{w}\), to uniform weights, where \(\sum_i w_i = 1\).
- For \(j\) in \(m\) boosting rounds, do the following:
a. Train a weighted weak learner: \(C_j = train(\boldsymbol{X},\boldsymbol{y},\boldsymbol{w})\).
b. Predict class labels: \(\boldsymbol{\hat{y}} = predict(C_j, \boldsymbol{X})\).
c. Compute weighted error rate: \(\epsilon = \boldsymbol{w}\cdot (\boldsymbol{\hat{y}} \neq \boldsymbol{y})\).
d. Compute coefficient: \(\alpha_j = 0.5 log \frac{1-\epsilon}{\epsilon}\).
e. Update weights: \(\boldsymbol{w} := \boldsymbol{w} \times exp(-\alpha_j \times \boldsymbol{\hat{y}} \times \boldsymbol{y})\).
f. Normalize weights to sum to 1: \(\boldsymbol{w} := \boldsymbol{w}/ \sum_i w_i \). - Compute the final prediction: \(\boldsymbol{\hat{y}} = (\sum_{j=1}^m(\alpha_j \times predict(C_j, \boldsymbol{X}))>0)\).
-
Python code for AdaBoost:
from sklearn.ensemble import AdaBoostClassifier
tree = DecisionTreeClassifier(criterion='entropy', random_state=1, max_depth=1)
ada = AdaBoostClassifier(base_estimator=tree, n_estimators=500, learning_rate=0.1, random_state=1)
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
Announcement: The content above is credited to many resources. All blogs on this website are study notes, not copyright publications.