What is Canopy Clustering

Short Answer
Canopy clustering is a pre-clustering algorithm, which performs clustering in two stages:
- Stage 1. Use an "unexpensive" distance measurement to roughly divide the data into overlapping subsets we call "canopies".
- State 1. Use an "expensive" distance measurement to perform an elaborate clustering.
Clustering algorithms depend heavily on distance measurement. There are so many different distance measurements, which you can find in a previous post.
https://dsworld.org/what-is-a-recommender-system/
Long Answer
-
First, let's make clear what is clustering. Clustering refers to a mechanism that involves the partitioning of the object into groups (named as clusters) such that the similarity between members of the same group is maximized and the similarity between members of different groups is minimized.
-
Clustering algorithms can be categorized as connectivity based clustering, centroid-based clustering, distribution-based clustering, density-based clustering, etc.
- Connectivity-based clustering also known as hierarchical clustering, is based on the core idea of objects being more related to nearby objects than to objects farther away. There are two subcatogeries of hierarchical clustering:
- Agglomerative (bottom-up) approach: each observation starts in its own cluster, and pairs of clusters are merged as one if they are close enough. Then moves up the hierarchy until result clustering meet the criterion set in advance.
- Divisive (top-down) approach: all observations start in one cluster, and splits are performed recursively as one moves down the hierarchy.
- All the merges and splits are determined in a greedy manner. In general, hierarchy clustering is time-consuming.
- Centroid-based clustering is based on the central vectors, which represent corresponding clusters. Point belongs to the cluster whose central vector is the closest one comparing to the other central vectors. k-means clustering is an example of this method.
- Distribution-based clustering is based on distribution models. Clusters are defined as objects most likely from the same distribution. Expectation-maximization algorithm is an example of this method.
- Density-based clustering groups together several closely placed points. DBSCAN, which we introduced in a prior post, is a good example of this method.
https://dsworld.org/what-is-the-dbscan-clustering-algorithm/
- Connectivity-based clustering also known as hierarchical clustering, is based on the core idea of objects being more related to nearby objects than to objects farther away. There are two subcatogeries of hierarchical clustering:
-
The canopy clustering algorithm is an unsupervised pre-clustering algorithm, which is used as preprocessing step for the k-means clustering, hierarchical clustering, etc. The main intention to use canopy clustering is to decrease computational cost.
-
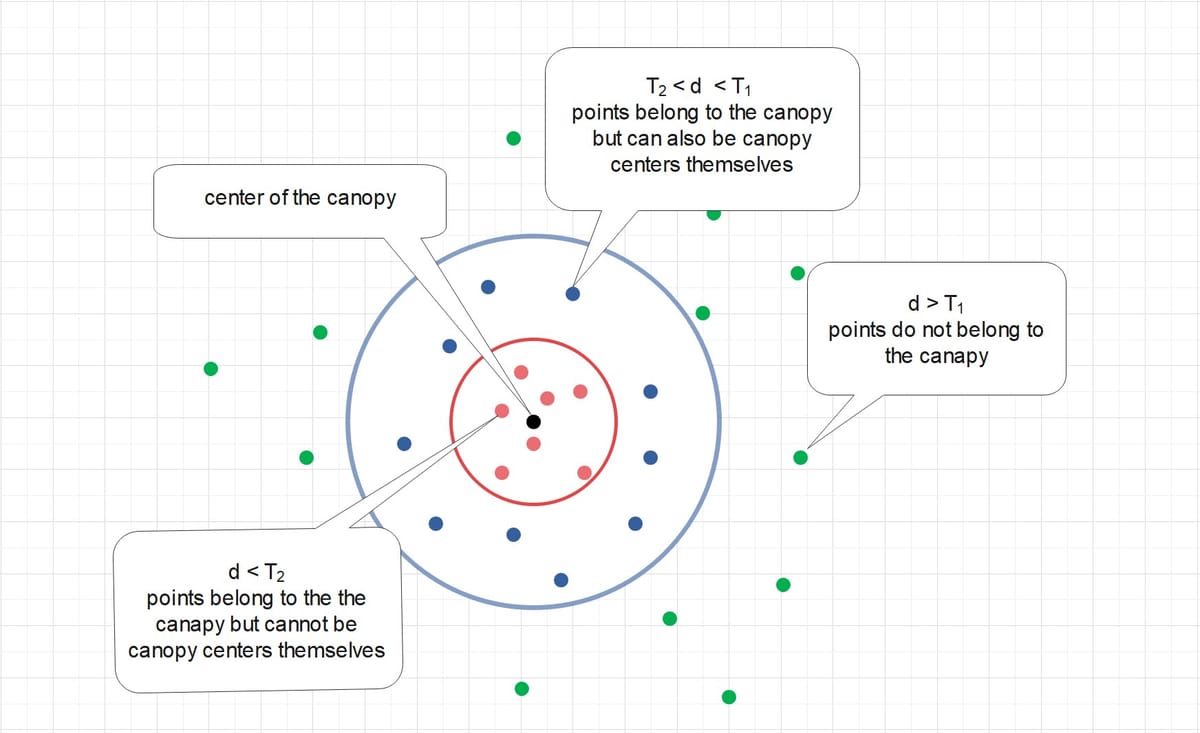
The algorithm proceeds as follows, using two thresholds \(T_{1}\) (the loose distance) and \(T_{2}\) (the tight distance), where \(T_{1} > T_{2}\).
- Begin with the set of all data points to be clustered.
- Pick a point (the black point in the figure, for example) from the set, and create a new canopy with this point as the center point of the canopy.
- For each point left in the set, assign it to the new canopy if the distance \(d\) between this point and the center point is less than the loss distance \(T_{1}\). (the red points and blue points in the figure)
- If the distance \(d\) is additionally less than the tight distance \(T_{2}\), remove it from the original set. (the red ones in the figure)
- Repeat Step 2 to Step 4, until there are no more data points in the set to be canopied.
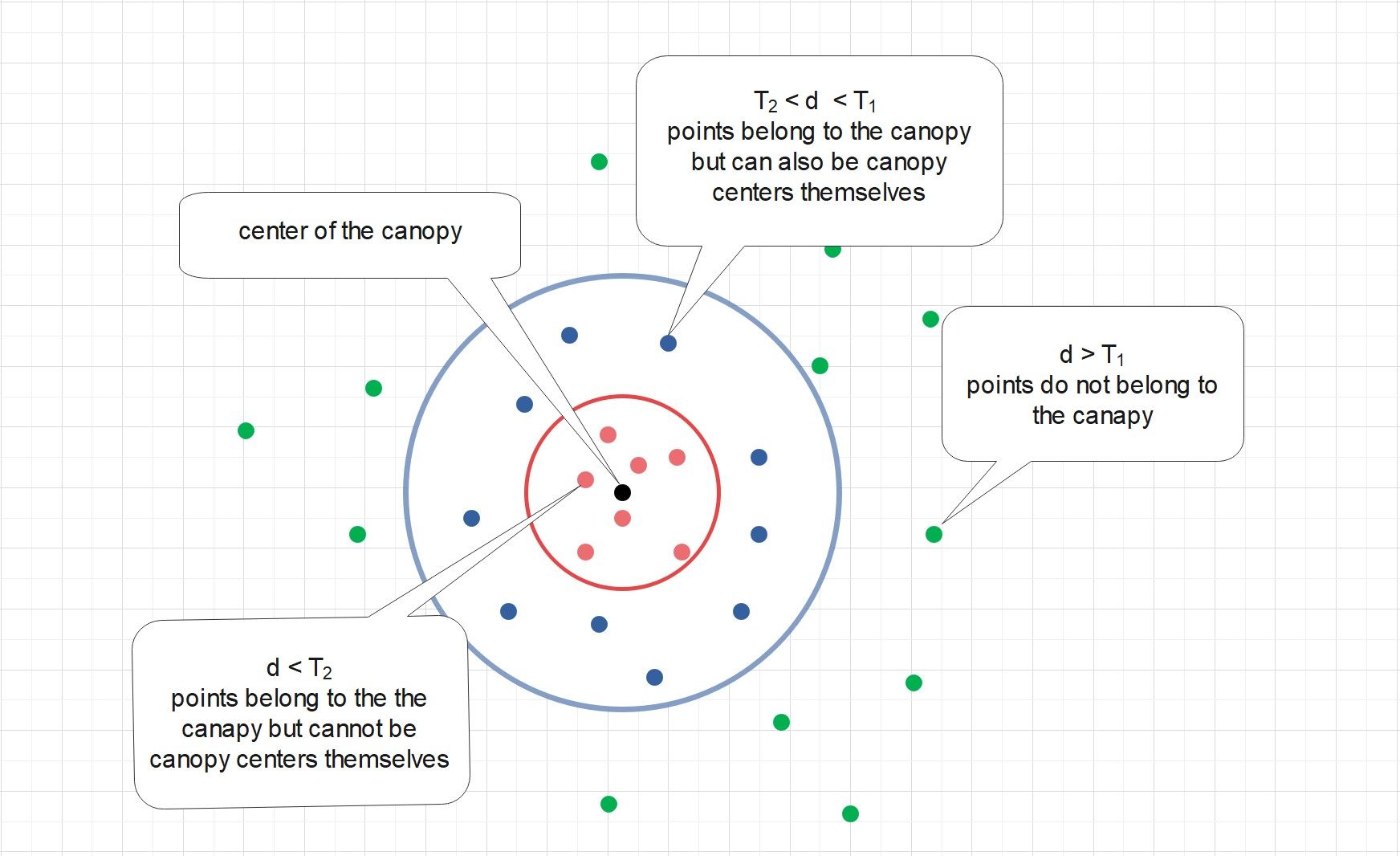
- Note that canopies may be overlapped, clustering hasn't been completed so far. In the last step, each canopy is re-clustered with more accurate and computationally expensive clustering algorithm, for instance k-means, to accomplish the final clustering.