DAD Notes IV: Deep Anomaly Detection Models

In this post, we discuss various Deep Anomaly Detection Models (DAD) classified based on the availability of labels and training objectives. For each model types domain, we discuss the following four aspects:
- Assumptions
- Type or model architectures
- Computational complexity
- Advantage and disadvantages
1. Supervised Deep Anomaly Detection
Supervised anomaly detection techniques are superior in performance compared to unsupervised anomaly detection techniques since these techniques use labeled samples. Supervised anomaly detection learns the separating boundary from a set of annotated data instances (training) and then, classify a test instance into either normal or anomalous classes with the learning model.
Assumptions: Deep supervised learning methods depend on separating data classes whereas unsupervised techniques focus on explaining and understanding the characteristics of data. Multi-class classification based anomaly detection techniques assume that the training data contains labeled instances of multiple normal classes. In general, supervised deep learning based classification schemes for anomaly detection have two sub-networks, a feature extraction network followed by a classifier network. Deep models require a substantial number of training samples to learn feature representations to discriminate various class instances effectively. Due to, the lack of availability of clean data labels supervised deep anomaly detection techniques are not so popular as semi-supervised and unsupervised methods.
Computational Complexity: The computational complexity of deep supervised anomaly detection methods based techniques depends on the input data dimension and the number of hidden layers trained using back-propagation input features. The computational complexity also increases linearly with the number of hidden layers and requires greater model training and update time.
Advantages and Disadvantages:
- The advantages of supervised DAD techniques are as follows:
-- Supervised DAD methods are more accurate than semi-supervised and unsupervised models.
-- The testing phase of classification based techniques is fast since each test instance needs to be compared against the precomputed model. - The disadvantages of Supervised DAD techniques are as follows:
-- Multi-class supervised techniques require accurate labels for various normal classes and anomalous instances, which is often not available.
-- Deep supervised techniques fail to separate normal from anomalous data if the feature space is highly complex and non-linear.
2. Semi-supervised Deep Anomaly Detection
Semi-supervised or DAD techniques assume that all training instances have only one class label. DAD techniques learn a discriminative boundary around the normal instances. The test instance that does not belong to the majority class is flagged as being anomalous. Common semi-supervised DAD model architectures include: AE-OCSVM, AE-SVM, DNN-SVM, DAE-KNN, DBN-Random Forest, AE-CNN, AE-DBN, AE-KNN, CNN-LSTM-SVM, etc.
Assumptions: Semi-supervised DAD methods are proposed to rely on one of the following assumptions to score a data instance as an anomaly.
- Proximity and Continuity: Points which are close to each other both in input space and learned feature space are more likely to share the same label.
- Robust features are learned within hidden layers of deep neural network layers and retain the discriminative attributes for separating normal from outlier data points.
Computational Complexity: The computational complexity of semi-supervised DAD methods based techniques is similar to supervised DAD techniques, which primarily depends on the dimensionality of the input data and the number of hidden layers used for representative feature learning.
Advantages and Disadvantages:
-
The advantages of semi-supervised deep anomaly detection techniques are as follows:
-- Generative Adversarial Networks (GANs) trained in semi-supervised learning models have shown great promise, even with very few labeled data.
-- Use of labeled data (usually of one class), can produce considerable performance improvement over unsupervised techniques. -
The disadvantages of semi-supervised deep anomaly detection techniques are as follows:
-- The hierarchical features extracted within hidden layers may not be representative of fewer anomalous instances hence are prone to the over-fitting problem.
3. Hybrid Deep Anomaly Detection
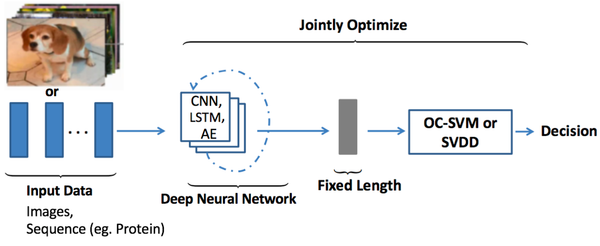
Deep learning models are widely used as feature extractors to learn robust features. In deep hybrid models, the representative features learned within deep models are input to traditional algorithms like one-class Radial Basis Function (RBF), Support Vector Machine (SVM) classifiers. The hybrid models employ two step learning and are shown to produce state-of-the-art results.
Assumptions:
The deep hybrid models proposed for anomaly detection rely on one of the following assumptions to detect outliers:
- Robust features are extracted within hidden layers of the deep neural network, aid in separating the irrelevant features which can conceal the presence of anomalies.
- Building a robust anomaly detection model on complex, high-dimensional spaces require feature extractor and anomaly detector.
Computational Complexity:
The computational complexity of a hybrid model includes the complexity of both deep architectures as well as traditional algorithms used within. Additionally, an inherent issue of non-trivial choice of deep network architechture and parameters which involves searching optimized parameters in a considerably larger space introduces the computational complexity of using deep layers within hybrid models. Furthermore considering the classical algorithms such as linear SVM which has prediction complexity of \( O(d) \) with d the number of input dimensions. For most kernels, including polynomial and RBF, the complexity is \( O(nd) \) where n is the number of support vectors although an approximation \( O(d^{2}) \) is considered for SVMs with an RBF kernel.
Advantages and Disadvantages
-
The advantages of hybrid DAD techniques are as follows:
-- The feature extractor significantly reduces the 'curse of dimensionality', especially in the high dimensional domain.
-- Hybrid models are more scalable and computationally efficient since the linear or nonlinear kernel models operate on reduced input dimension. -
The disadvantages of hybrid DAD techniques are as follows:
-- The hybrid approach is suboptimal because it is unable to influence representational learning within the hidden layers of feature extractor since generic loss functions are employed instead of the customized objective for anomaly detection.
-- The deeper hybrid models that tend to perform better introduces computational expenditure.
4. One-class Neural Networks (OC-NN) for Anomaly Detection
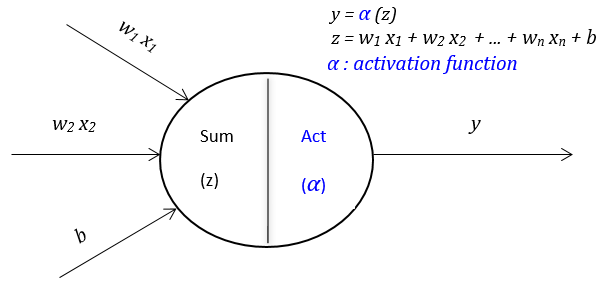
One-class neural networks (OC-NN) combines the ability of deep networks to extract a progressively rich representation of data along with the one-class objective, such as hyperplane or hypersphere to separate all the normal data points from the outliers. The OC-NN approach is novel for the following crucial reason: data representation in the hidden layer is learned by optimizing the objective function customized for anomaly detection. Some research demonstrate that OC-NN can achieve comparable or better performance than existing state-of-the-art methods for complex datasets, while having reasonable training and testing time compared to the existing methods.
Assumptions: The OC-NN models proposed for anomaly detection rely on the following assumptions to detect outliers:
- OC-NN models extract common factors of variation within the data distribution within the hidden layers of the deep neural network.
- Performs combined representation learning and produces and outlier score for a test data instance.
- Anomalous samples do not contain common factors of variation and hence hidden layers fail to capture the representations of outliers.
Computational Complexity: The computational complexity of an OC-NN model as against the hybrid model includes only the complexity of the deep network of choice. OC-NN models do not require data to be stored for prediction, thus have very low memory complexity. However, it is evident that the OC-NN training time is proportional to the input dimension.
Advantages and Disadvantages:
- The advantages of OC-NN are as follows:
-- OC-NN models jointly train a deep neural network while optimizing a data-enclosing hypersphere or hyperplane in output space.
-- OC-NN propose an alternating minimization algorithm for learning the parameters of the OC-NN model. We observe that the subproblem of OC-NN objective is equivalent to a solving a quantile selection problem which is well defined. - The disadvantages of OC-NN are as follows:
-- Training times and model update time may be longer for high dimensional input data.
-- Model updates would also take longer time, given the change in input space.
5. Unsupervised Deep Anomaly Detection
Unsupervised DAD is an essential area of research in both fundamental machine learning research and industrial applications. Several deep learning frameworks that address challenges in unsupervised anomaly detection are proposed and shown to produce a state-of-the-art performance. Autoencoders are the fundamental unsupervised deep architechtures used in anomaly detection.
Assumptions: The deep unsupervised models proposed for anomaly detection rely on one of the following assumptions to detect outliers:
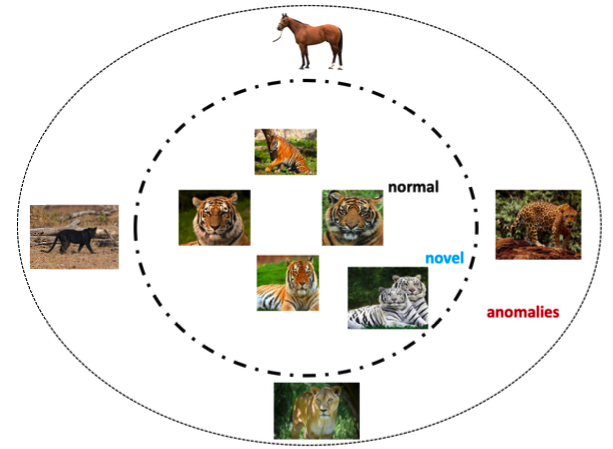
- The "normal" regions in the original or latent feature space can be distinguished from "anomalous" regions in the original or latent feature space.
- The majority of the data instances are normal compared to the reminder of the data set.
- Unsupervised anomaly detection algorithm produces an outlier score of the data instances based on instrinsic properties of the dataset such as distances or dentsities. The hidden layers of deep neural network aim to capture these intrinsic properties within the dataset.
Computational Complexity: The autoencoders are the most common architecture employed in outlier detection with quadratic cost, the optimization problem is non-convex, similar to any other neutral network architecture. The computational complexity of the model depends on the number of operations, network parameters, and hidden layers. However, the computational complexity of training an autoencoder is much higher than traditional methods such as Principal Component Analysis (PCA) since PCA is based on matrix decomposition.
Advantages and Disadvantages:
- The advantages of unsupervised deep anomaly detection techniques are as follows:
-- Learns the inherent data characteristics to separate normal from an anomalous data point. This technique identifies commonalities within the data and facilitates outlier detection.
-- Cost effective technique to find the anomalies since it does not require annotated data for training the algorithms. - The disadvantages of unsupervised deep anomaly detection techniques are as follows:
-- Often it is challenging to learn commonalities within data in complex and high dimensional space.
-- While using autoencoders the choice of right degree of compression, i.e., dimensionality reduction is often a hyper-parameter that requires tuning for optimal results.
-- Unsupervised techniques are very sensitive to noise, and data corruption and are often less accurate than supervised or semi-supervised techniques.
6. Miscellaneous Techniques
Now we list some DAD techniques which are shown to be effective and promising.
6.1 Transfer Learning-based Anomaly Detection
Deep learning for long has been criticized for the need to have enough data to produce good results. Transfer learning is an essential tool in machine learning to solve the fundamental problem of insufficient training data. It aims to transer the knowledge from the source domain to target domain by relaxing the assumption that training and future data must be in the same feature space and have the same distribution.
6.2 Zero Learning-based Anomaly Detection
Zero Shot Learning (ZSL) aims to recognize objects never seen before within training set. ZSL achieves this in two phases:
- The knowledge about the objects in natural language descriptions or attributes (commonly known as meta-data) is captured.
- This knowledge is then used to classify instances among a new set of classes.
This seeting is important in the real world since one may not be able to obtain images of about the data instances.
6.3 Ensemble-based Anomaly Detection
A notable issue with deep neural networks is that they are sensitive to noise within input data and often require extensive training data to perform robustly. In order to achieve robustness even in noisy data an idea to randomly vary on the connectivity architecture of the autoencoder is shown to obtain significantly better performance. Autoencoder ensenbles consisting of various randomly connected autoencoders are experimentd to achieve promising results on several benchmark datasets. The ensemble approaches are still an active area of research which has been shown to produce improved diversity, thus avoid overfitting problem while reducing training time.
6.4 Clustering-based Anomaly Detection
Several anomaly detection algorithms based on clustering have been proposed in literature. Clustering involves grouping together similar patterns based on features extracted detect new anomalies. The time and space complexity grows linearly with number of classes to be clustered, which renders input data is reduced extracting features within the hidden layers of deep neural network which ensures scalability for complex and high dimensional datasets. Several works rely on variants of hybrid models along with auto-encoders for obtaining representative features for clustering to find anomalies.
6.5 Deep Reinforcement Learning (DRL) based anomaly detection
Deep reinforcement learning (DRL) methods have attracted significant interest due to its ability to learn complex behaviors in high-dimensional data space. The DLR based anomaly detector does not consider any assumption about the concept of the anomaly, the detector identifies new anomalies by consistently enhancing its knowledge through reward signals accumulated. DRL based anomaly detection is a very novel concept which requires further investigation and identification of the research gap and its application.
6.6 Statistical Techniques Deep Anomaly Detection
Hilbert transform is a statistical signal processing technique which derives the analytic representation of a real-valued signal. This property can be leveraged for real-time detection of anomalies in health-related time series dataset and is shown to be a very promising technique. The algorithm combines the ability of wavelet analysis, neural networks and Hilbert transform in a sequential manner to detect real-time anomalies.