DAD Notes I: Introduction to Deep Learning for Anomaly Detection

In data analysis, anomaly detection (also referred to as outlier detection) is generally understood to be the identification of rare items, events or observations which deviate significantly from the majority of the data. Anomalies can be caused by errors in the data but sometimes are indicative of a new, previously unknown, underlying process.
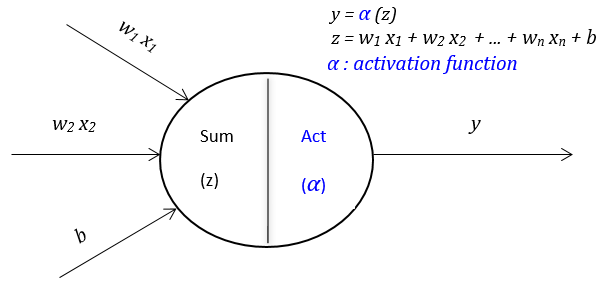
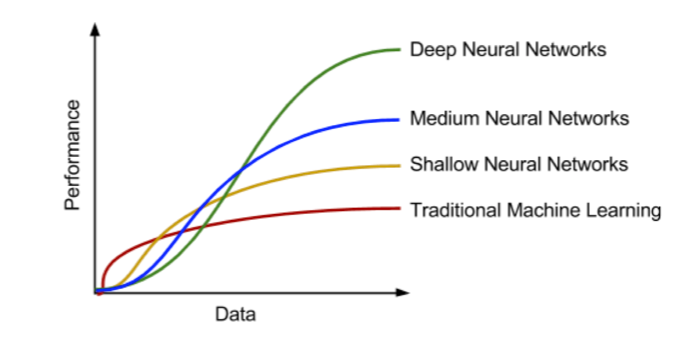
In the broader field of maching learning, the recent years have witnessed a proliferation of deep neural networks, with unprecedented results across various application domains. Deep learning is a subset of machine learning that achieves good performance and flexibility by learning to represent the data as a nested hierarchy of concepts within layers of the neural network. Deep learning outperforms the traditional machine learning as the scale of data increases as illustrated in the figure below.
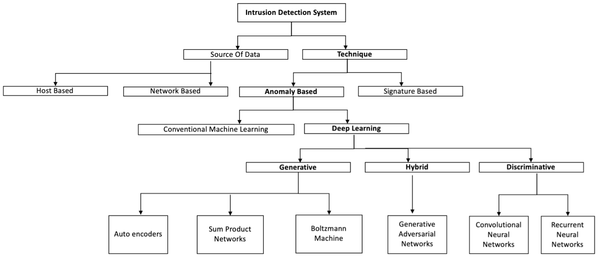
Anomaly detection is applicable in a very large number and variety of domains, such as cyber-security intrusion detection, fraud detection, fault detection, system health monitoring, event detection in sensor networks, detecting ecosystem disturbances, defect detection in images using machine vision, medical diagnosis and law enforcement.
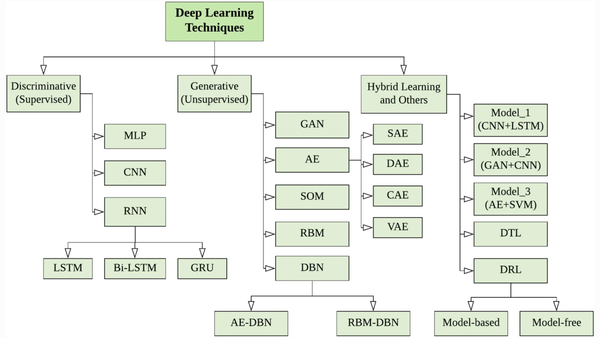
In recent years, deep learning-based anomaly detection algorithms have become increaingly popular and applied for a diverse set of tasks, studies have shown that deep leaning completely supasses traditional methods (Javaid et al., 2016). Considering the proliferation in this area, Chalapathy and Chawla write a review on deep learning for anomaly detection (2019).
Let's started from some basic concepts of anomaly detection. Anomalies are also referred to as abnormalities, deviants, or outliers in the data mining and statistics literature.
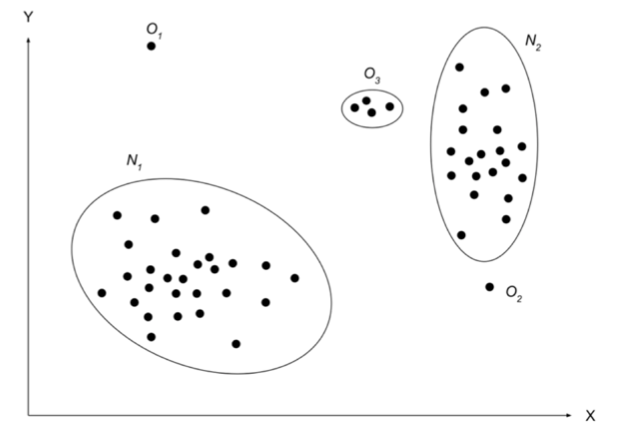
As illustrated in the figure below, \(N_{1}\) and \(N_{2}\) are regions consisting of a majority of observations and hence considered as normal data instance regions, whereas the region \(O_{3}\), and data points \(O_{1}\) and \(O_{2}\) only have a few data points which are located further away from the bulk of data points and hence are considered anomalies.
Anomalies arise due to several reasons, such as malicious actions, system failures, intentional fraud. These anomalies reveal exciting insights about the data and are often convey valuable information about data. Therefore, anomaly detection considered an assential step in various decision-making systems.
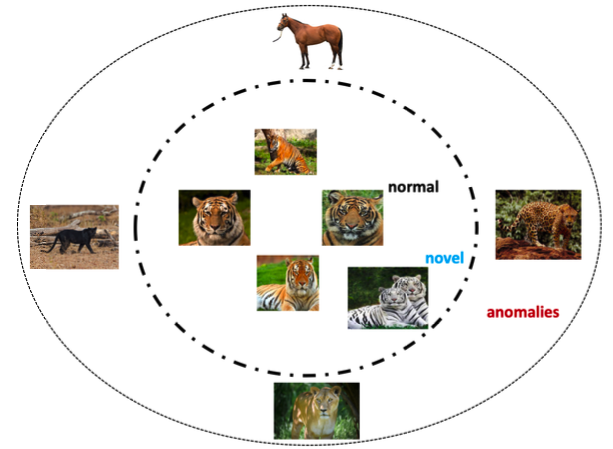
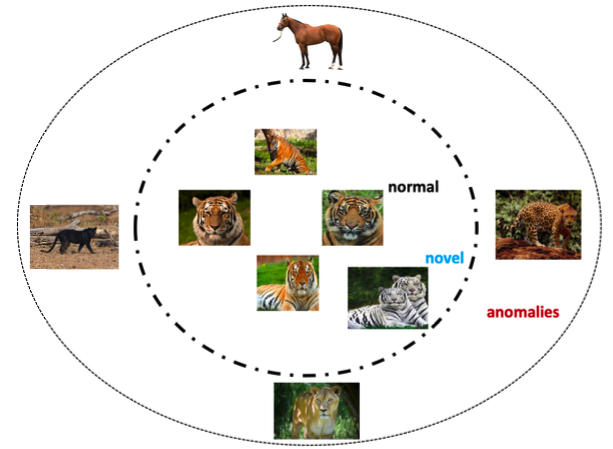
Another concept that could sometimes be confused with anomaly detection is novelty detection, which is the identification of a novel or unobserved patterns in the data. A novelty score may be assigned for some exotic data points, using a decision threshold. Usally novelties are not so significantly deviate from the decision threshold as anomalies or outliers do. For example, in the figure below the image of a white tiger may be considered as a novelty, while the images of horse, panther, lion and cheetah are considered as anomalies provied that regular tigers are normalies.
Recent years, deep-learning architectures such as deep neural networks, deep belief networks, deep reinforcement learning, recurrent neural networks and convolutional neural networks have been widely applied to fields including computer vision, speech recognition, natural language processing, machine translation, bioinformatics, drug design, medical image analysis, climate science, material inspection and board game programs, where they have produced results comparable to and in some cases surpassing human expert performance.
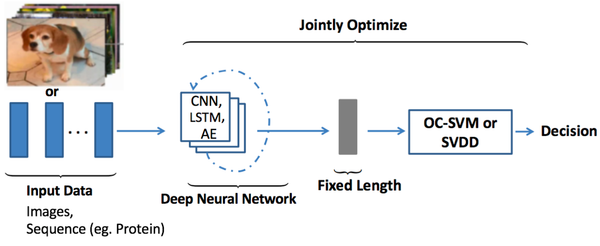
Researchers and practitioners are increasingly considering using deep learning for anormaly detection and have made some encouraging progress.
Despite those achievements, there is a relative scarcity of deep learning approaches for anomaly detection. We hope that this article could provide a comprehensive reference for researchers and engineers aspiring to leverage deep learning for anomaly detection.
Deep learning-based anomaly detection is associated with many different models usually depending on different types of anomaly and applications.
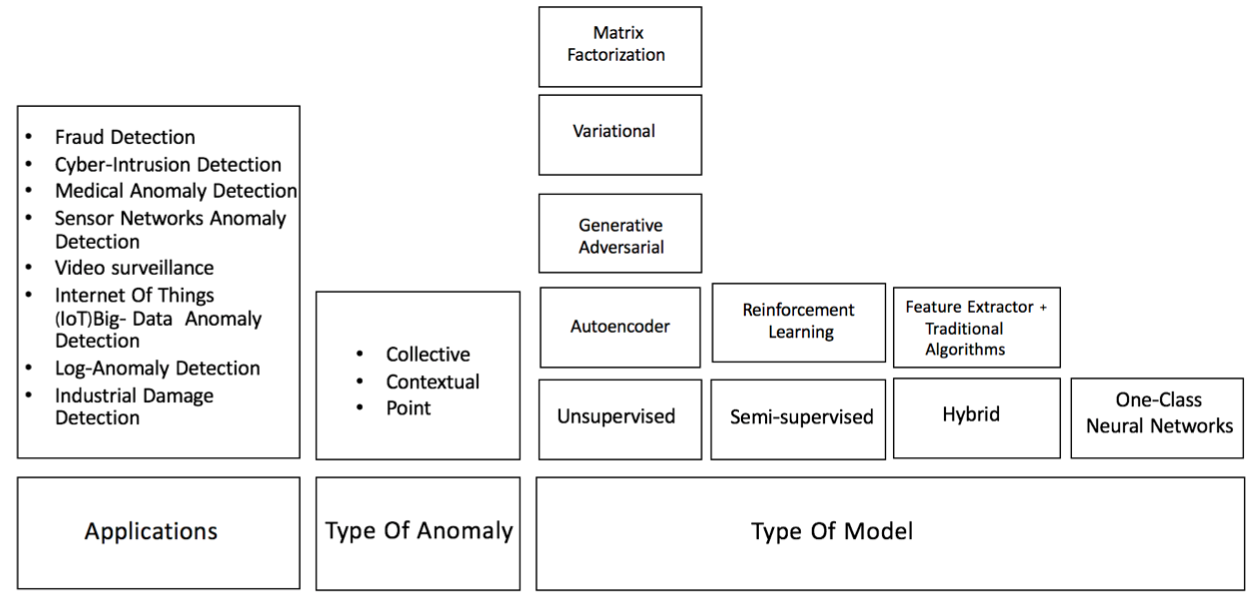
In sebseuent blogs, we will identify the various aspects that determine the formulaiton ofthe problem and highlight the richness can complexity accociated with anomaly detection. Additionally we will briefly describe the different application domains to which deep learning-based anomaly detection has been applied.