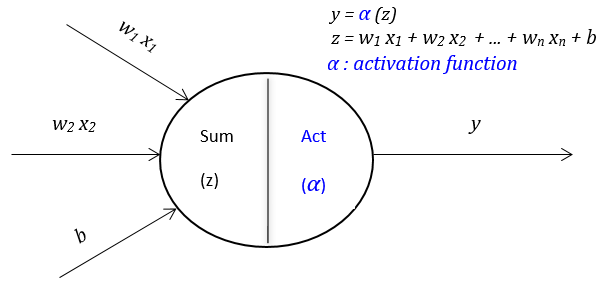
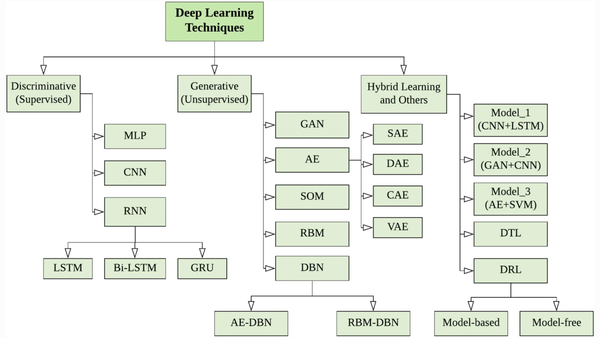
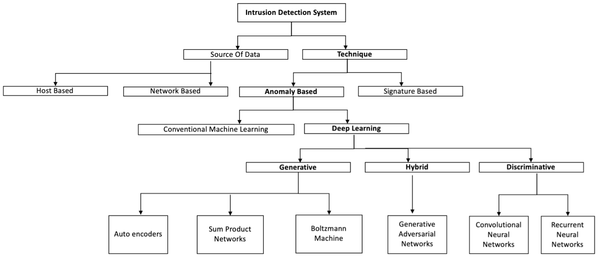
DAD Notes II: Different Aspects of Deep Learning-based Anomaly Detection

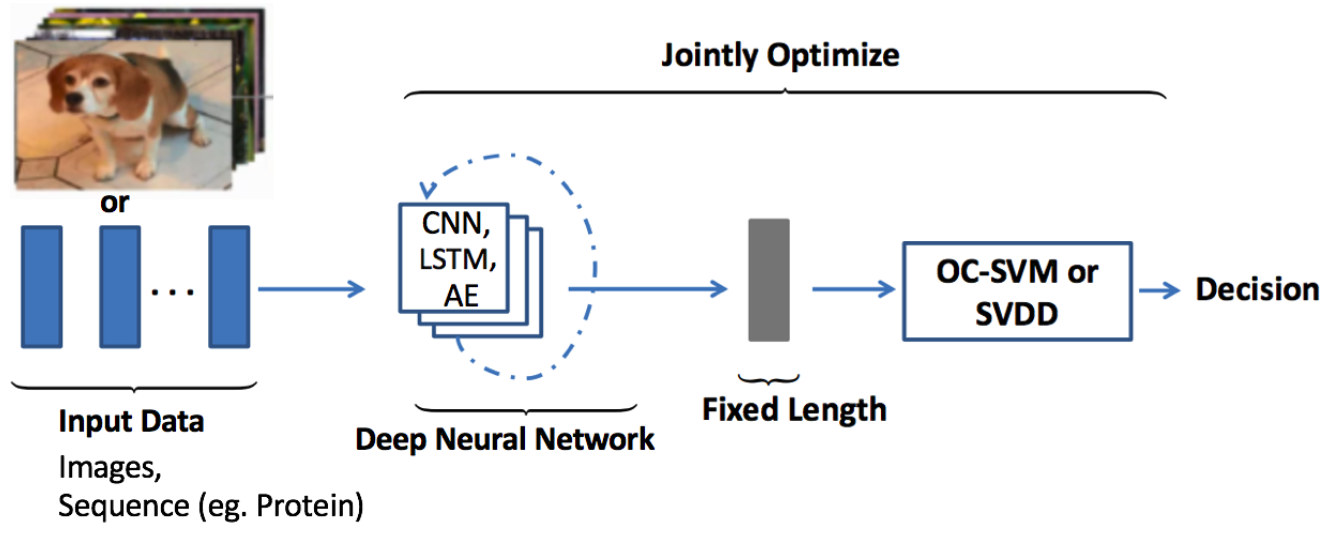
Varous deep learning mothods are used to detect anomaly. When we encounter the difficulty to choose an apropriate one, we can always find some cludes from the nature of input data, the availability of labels, the training objective, the type of anomaly, and the output of DAD techniques.
1. Nature of Input Data
The choice of a deep neural network architecture in deep anomaly detection (DAD) methods primarily depends on the nature of input data. Input data can be broadly classified into sequential or non-sequential data.
| Type of Data | Examples | DAD model architecture |
|---|---|---|
| Sequential | voice, text, music, time series, protein sequences | CNN, RNN, LSTM |
| Non-Sequential | imanges, sensor, cross-section data | CNN, AE and its variants |
Additionally input data depending on the number of features can be further classified into either low or high-demensional data. Generally, deeper networks are shown to produce better performance on high dimensional data.
2. Availability of Labels
Labels indicate whether a chosen data instance is normal or not. Anomalies are rare entiteis hence it is challenging to obtain their labels and often need expertise. Furthermore, anomalous behavior may change over time and the boundary between normal and anomalous behavior is often not precisely defined.
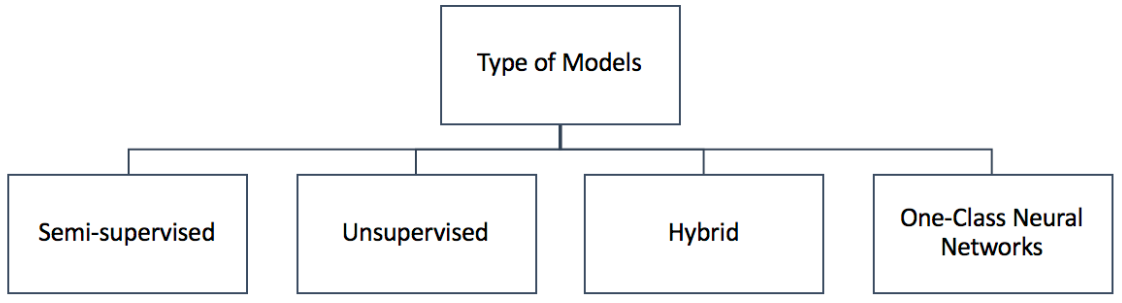
Deep anomaly detection models can be broadly classified into three categories based on the extent of availability of labels: supervised deep anomaly detection, semi-supervised deep anomaly detection, and unsupervised deep anomaly detection.
2.1 Supervised Deep Anomaly Detection
Supervised deep anomaly detection involves training a deep supervised binary or multi-class classifier, using labels of both normal and anomalous data instances. This mothod is not as popular as semi-supervised or unsupervised methods, owing to the lack of availability of labeled training samples. Moreover, the performance of deep supervised classifier used an anomaly detector is sub-optimal also due to class imbalance, which need specific techniques such as random over sampling, synthetic over sampling, penalized algorithms, and so on.
2.2 Semi-Supervised Deep Anomaly Detection
The labels of normal instances are far more easy to obtain than anomalies, as a result, semi-supervised DAD techniques are more widely adopted, there techniques leverage existing normal labels to separate outliers. One common way of using deep autoencoders in anomaly detection is to train them in a semi-supervised way on data samples with no anomalies. With sufficient training samples, of normal class autoencoders would produce low reconstruction errors for normal instances, over unusual events.
2.3 Unsupervised Deep Anomaly Detection
Unsupervised deep anomaly detection techniques detect outliers solely based on intrinsic properties of the data instances. Unsupervised DAD techniques are used in automatic labeling of unlabelled data samples since labeled data is very hard to obtain. Variants of unsupervised DAD models are shown to outperform traditional methods such as PCA, SVM, and Isolation Forest techniques in applications such as health and cyber-security.
Autoencoders are the core of all Unsupervised DAD models. These models assume a high prevalence of normal instances than abnormal data instances failing which would result in high false positive rate. Additionally unsupervised learning algorithms such as Restricted Boltzmann Machine (RBM), Deep Boltzmann Machine (DBM), Deep Belief Network (DBN), Recurrent Neural Network (RNN), and Long Short Term Memory networks (LSTM) which are used to detect outliers are discussed in the Appendix.
3. The Training Objective
What is your training objective? To extract features or to get the final label? Two main categories of DAD techiniques base on training objectives are: Deep Hybrid Models (DHM) and One Class Neural Networks (OC-NN).
3.1 Deep Hybrid Models (DHM)
Deep hybrid models for anomaly detection use deep neural networks mainly autoencoders as feature extractors, the features learned within the hidden representations of autoencoders are input to traditional anomaly detection algorithms such as One-Class SVM (OC-SVM) to detect anomaly. The figure below illustrates the deep hybrid model architecture used for anomaly detection.
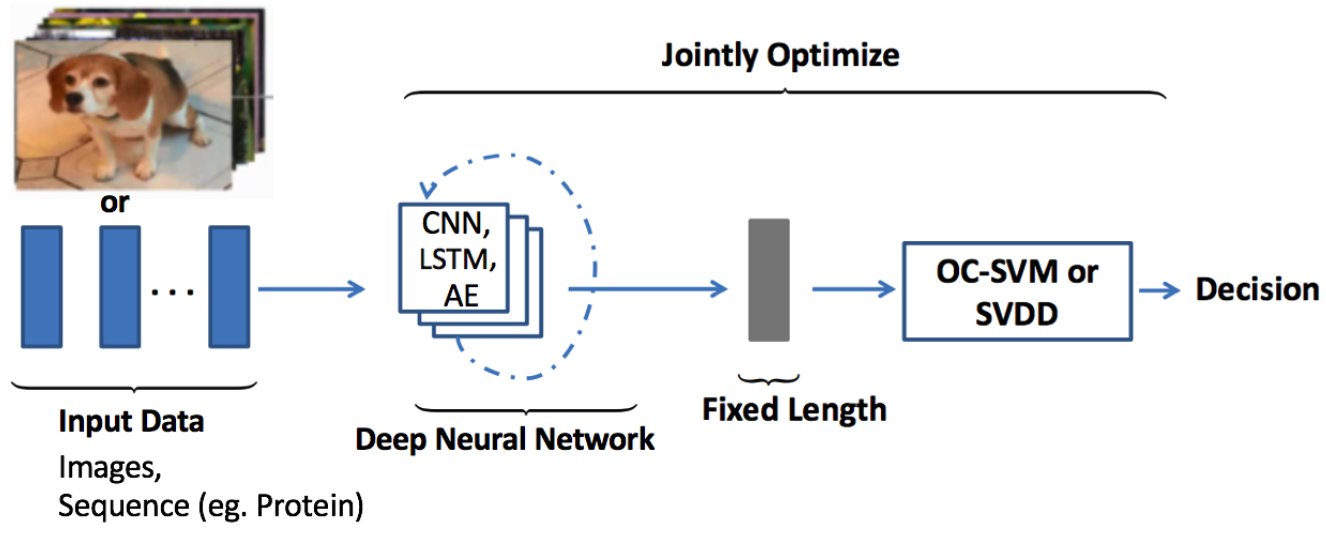
Following the success of transfer learning to obtain rich representative features from models pre-trained on large data-sets, hybrid models have also employed these pre-trained transfer learning models as feature extractors with great success. A notable shortcoming of these hybrid approaches is the lack of trainable objective customized for anomaly detection, hence these models fail to extract rich differential features to detect outliers. In order to overcome this limitation customized objective for anomaly detection such as Deep One-Class Classification (DOCC) and One Class Neural Networks (OC-NN) are introduced.
3.2 One-Class Neural Networks (OC-NN)
One class neural network (OC-NN) methods are inspired by kernel-based one-class classification which combines the ability of deep networks to extract a progressively rich representation of data with one-class objective of creating a tight envelope around normal data. The OC-NN approach breaks new ground for the following crucial reason: data representation in the hidden layer is driven by the OC-NN objective and is thus customized for anomaly detection. This is a departure from other approaches which use a hybrid approach of learning deep features using an autoencoder and then feeding the features into a separate anomaly detection method like One-Class SVM (OC-SVM). Another variant of one class neural network architecture Deep Support Vector Description (Deep SVDD) trains deep neural network to extract common factors of variation by closely mapping the normal data instances to the center of sphere, and is shown to produce performance improvements on MNIST and CIFAR-10 datasets.
Let's summary up all DAD methods we mentioned in the previous paragraphs into the diagram below.
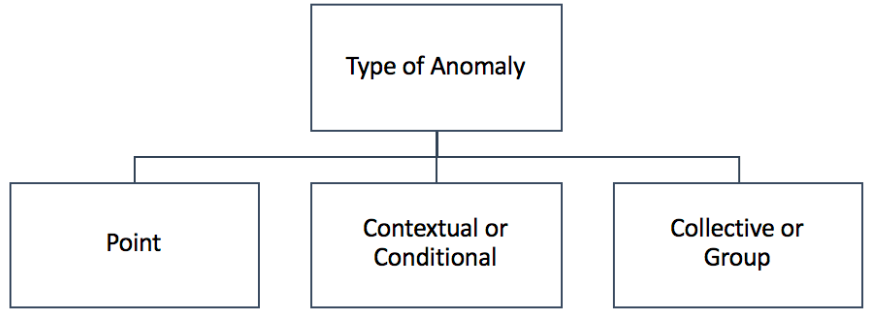
4. Type of Anomaly
Anomalies can be broadly classified into three types: point anomalies, contextual anomalies and collective anomalies. DAD methods have been shown to detect all three types of Anomalies with great success.
4.1 Point Anomalies
The majority of work in literature focuses on point anomalies. Point anomalies often represent an irregularity or deviation that happens randomly and may have no particular interpretation. For instance, in the figure below a credit card transaction with high expenditure recorded at Monaco restaurant seems a point anomaly since it significantly deviates from the rest of the transaction.

4.2 Contextual Anomaly Detection
A contextual anomaly also known as the conditional anomaly is a data instance that could be considered as anomalous in some specific context. Contextual features, normally used are time and space. While the behavioral features may be a pattern of spending money, the occurrence of system log events or any feature used to describe the normal behavior.
The figures below illustrate the example of a contextual anomaly considering temperature data indicated by a drastic drop just before June, which is not regarded to be normal during this time.
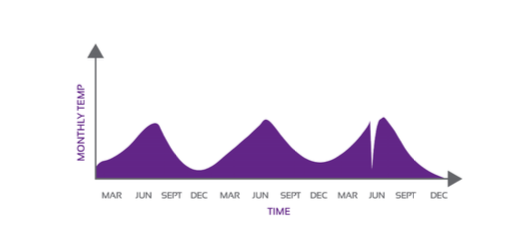
4.3 Collective or Group Anomaly Detection.
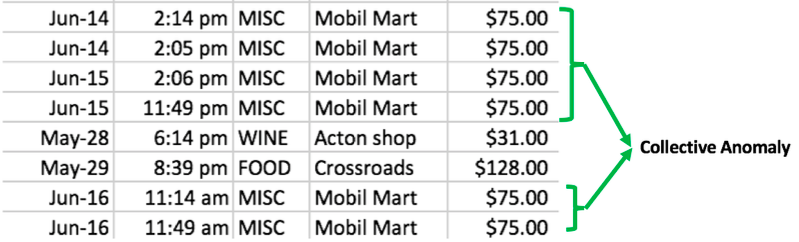
Anomalous collections of individual data points are known as collective or group anomalies, wherein each of the individual points in isolation appears as normal data instances while observed in a group exhibit unusual characteristics. Let us revisit the previous credit card fraud example. The same numbers ($75) appearing in a row look suspicious, they seem to be a candidate for collective or group anomaly. Group anomaly detection with an emphasis on irregular group distributions.
5. Output of DAD Techniques
A critical aspect of anomaly detection methods is the way in which the anomalies are detected. Generally, the outputs produced by anomaly detection methods are either anomaly scores or binary labels.
5.1 Anomaly Score
Anomaly score describes the level of outlierness for each data point. The data instances may be ranked according to anomalous score, and a domain-specific threshold will be selected by subject matter expert to identify the anomalies. In general, decision scores reveal more information than binary labels.
5.2 Labels
Instead of assigning scores, some techniques may assign a category label as normal or anomalous to each data instance. Unsupervised anomaly detection techniques using autoencoders measure the magnitude of the residual vector for obtaining anomaly scores, later on, the reconstruction errors are either ranked or thresholds by domain experts to label data instances.
We plan to conclude our introduction to DAD here, because there are so many concepts and methods introduced in this part of the review. In the next part, we will discuss several attractive applications of DAD.